据开发人员西蒙・威利森(Simon Willison)在自己的博客中称,他成功在自己的笔记本电脑上运行了 Meta 的 130 亿参数模型 LLaMA-13B,这意味着大型语言模型已经可以跑在消费级硬件上了。
他还称,LLaMA-13B 在大多数基准测试上的表现都优于拥有 1750 亿个参数的大型语言模型 GPT-3,LLaMA-65B 甚至可与谷歌的 Chinchilla-70B 和 PaLM-540B 模型竞争。
一、Mac 能运行 130 亿参数大模型,只需 8GB 空间
一名软件开发人员乔治・格尔加诺夫(Georgi Gerganov)发布了一款名为 “llama.cpp” 的工具,该工具可助开发者在 MacBook 上运行 AI 大型语言模型 LLaMA。
LLaMA 全称为 “Large Language Model Meta AI”,即 Meta 大型语言模型,其参数量从 70 亿到 650 亿不等,当参数越大时,模型所占用的空间就越多,运行时所消耗的算力也就越大。llama.cpp 的主要目标就是在 MacBook 上使用 4-bit 量化运行大型语言模型。4-bit 量化是一种减小模型大小的技术,以便模型可以在功能较弱的硬件上运行,它还能减少磁盘上的模型大小:将 LLaMA-7B 减少到 4GB、LLaMA-13B 减少到 8GB 以下。
据 AI 开发者西蒙・威利森(Simon Willison)称,去年 8 月时发布的文本转图像模型 Stable Diffusion 开启了对于生成式 AI 的全新浪潮,ChapGPT 的出现则将其推向了超速发展。如今,对于大型语言模型而言,类似于 Stable Diffusion 的时刻再次发生了。
他称自己第一次在自己的电脑上运行了类 GPT-3 语言模型。
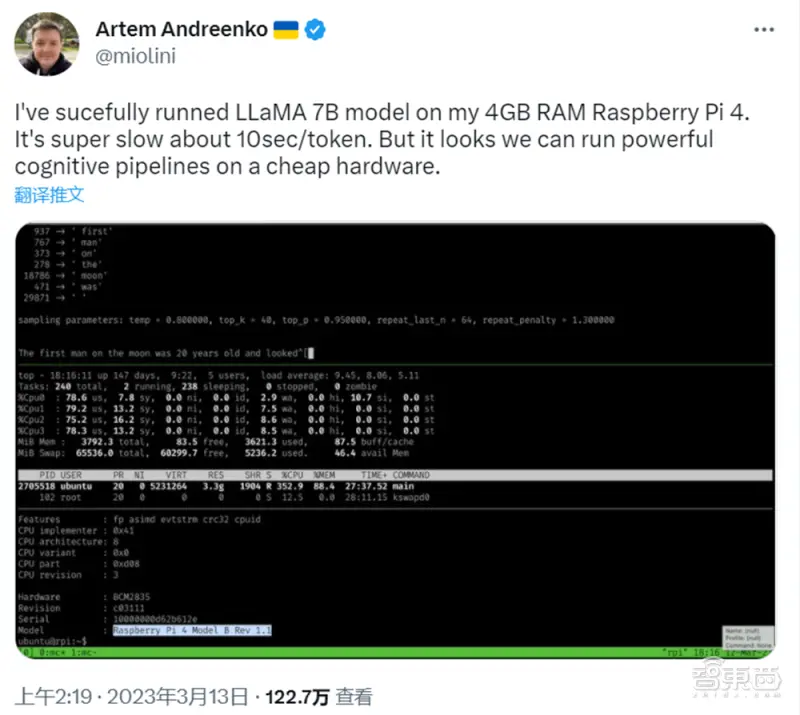

▲阿特姆・安德林科(Artem Andreenko)在 4GB RAM 的 Raspberry Pi 4 上运行 LLaMA 7B
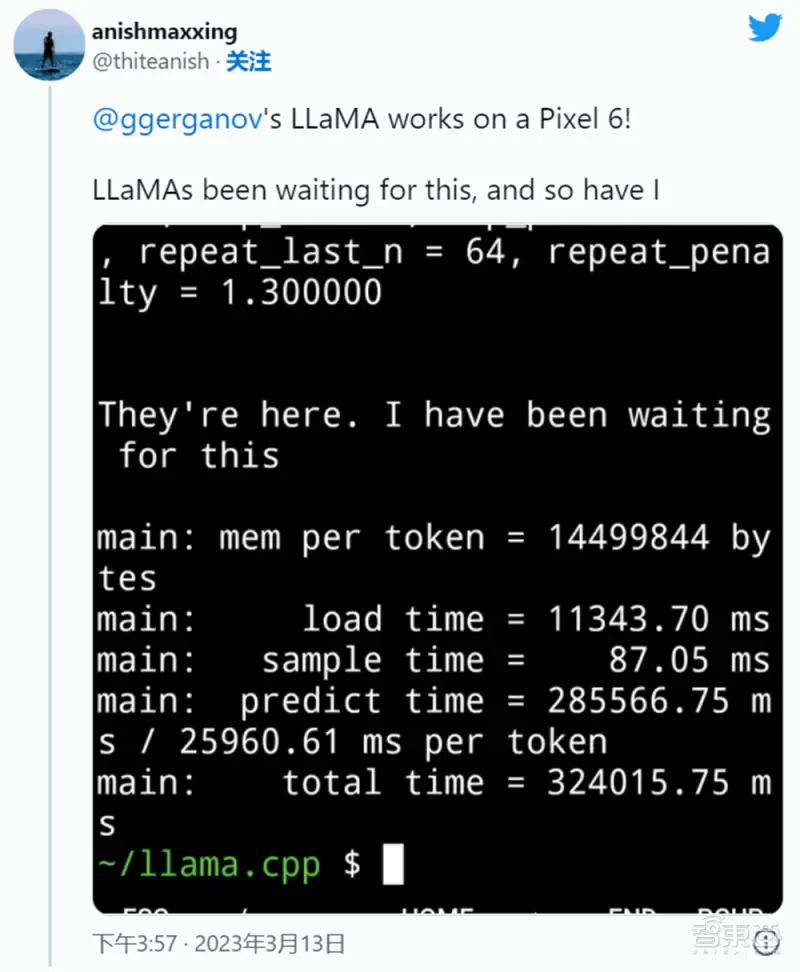
▲阿尼什・泰特(Anish Thite) 让它在 Pixel 6 手机上运行
威利森称,GPT-3 这样的语言模型为 ChatGPT 等工具提供技术支撑,它比图像生成模型更大,构建和运行成本也更高。
大型语言模型中大部分都是由 OpenAI 等私人组织构建的,并且一直受到严格控制 —— 只能通过他们的 API 和 Web 界面访问,不会发布给任何人在他们自己的电脑上运行。即使个人可以获得 GPT-3 模型,也无法在自己的硬件上运行,因为运行模型一般需要多个英伟达 A100 级 GPU(Graphics Processing Unit,即图形处理器),单个售价超 8000 美元。
而如今,威利森可以在自己的电脑上运行 LLaMA-7B 模型,并将它升级到 13B 模型。他之前认为还需要几年时间才能在自己的硬件上运行 GPT-3 类模型,但如今已经可以做到了。语言模型的成本已经下降到个人电子设备也可用的地步。经过 4-bit 量化之后,模型被缩小,LLaMA 甚至可以在配备 M1 芯片的 MacBook 上运行。
二、大型语言模型失去保护屏障,须合理使用
与此同时,威利森认为在现实生活场景中,人们完全有可能利用语言模型来做一些不好的事情。比如编写垃圾邮件,制造情感骗局,甚至还可能自动生成激进言论。
对生成式 AI 而言,编造一些虚假信息实在太容易了,并且人们也区分出来。在此之前,OpenAI 还对人们与这些模型的交互行为进行有选择的防御,但当普通人都能在自己的消费级硬件上运行这些语言模型时,又该怎么办呢?
在威利森看来,如果不将大语言模型往积极的方向加以引导的话,人们很容易会在使用过程中陷入到它的陷阱中去,要么认为生成式 AI 有害,要么认为它浪费了自己的时间。
威利森称自己如今每天都在根据自己的目的来选择使用生成式工具。他上周用 ChapGPT 来教自己学习 AppleScript 用以编写 Mac 系统的运行脚本。在 ChapGPT 的帮助下,他不到一小时就发布了一个新项目。
威利森认为当前人们的首要任务是找出最有建设性方法来使用 ChatGPT。
结语:大型语言模型限制被打破,平替 ChatGPT 有望实现
尽管目前在 MacBook 上运行 LLaMA 的步骤依然繁琐复杂,但威尔森已在自己的博客中给出了详尽的步骤说明。相信在开源社区的不断开发之下,LLaMA 会变得更易上手,操作更加便捷。LLaMA 在 llama.cpp 的帮助下,有望成为 “平替版 ChatGPT”,人们通过消费级电子产品也能自如使用大模型。
来源:智东西
如若转载,请注明出处:https://www.zhangzs.com/452567.html
 微信扫一扫
微信扫一扫 
