ChatGPT 是如何学习的?
1/6、多年以后……
多年以后,面对长长的领失业救济金队伍,人们将会回想起 2022 年 12 月,不是因为大感染,而是初次体验 ChatGPT。那时,人们感受到的,还不是旧世界的行将崩塌,而是对新世界到来的惊叹。
请允许我用这样一个烂俗的开头,因为大部分人可能都低估了 ChatGPT 对未来生活的改变,以为不过是一个更智能的搜索引擎,只有这句话才是最恰当的表达。
当然,如果觉得太悲观,或者机器代替人类的思路太俗套,我们也可以给自己的晚年换一个喜剧的结局:
多年以后,面对不需要上班就能领到工资的银行卡,人们将会回想起 2022 年 12 月……
ChatGPT 对于人类到底是悲剧还是喜剧,并不取决于技术本身,而在于我们每一个人如何对待它,但毫无疑问的是,这将是人工智能诞生以来,人类的工作第一次真正接近被大规模替代的时点 —— 不是部分工作被替代,而是大规模被替代的开始。
为了消除这种深深的恐惧,我很想知道 ChatGPT 到底是如何学习的,于是花了几天时间看了一些技术资料,大致理解了机器学习的过程。
没想到恐惧没有消除,反而多了几份敬意,敬意是送给 ChatGPT 算法的设计者,这真是一个天才的想法,而恐惧是我再次确信,不是少数专业工作者被替代,而是大量的普通白领。
这一篇文章,我想从 ChatGPT 的底层逻辑 ——“学习方法” 入手,谈谈我为什么这么认为。
不过,在介绍核心内容之前,我先简单谈一谈 ChatGPT 跟以前的 AI 有什么根本的不同。
2/6、决策式 AI 和生成式 AI
我们比较熟悉的 AI 已经成功应用的领域,包括人脸识别,自动驾驶、精准广告推送、风险评级,这些领域都有一个共同点 —— 判断与决策,所以称之为 “决策式 AI(Discriminant Model)”.
而 ChatGPT 应用的是另一个领域:生成式 AI,首先要理解文本的要求,判断自己的任务,检索相关的内容。这些跟决策式 AI 并没有什么不同,只是 ChatGPT 多了一步,它还要生成全新的内容,需要预测对方的理解偏好,将回复内容变成流畅的文本或有意义的图片、视频。
决策式 AI 使用的是 “条件概率”,一件事发生后,另一件事发生的概率,对于某些特定的场景,即使是最复杂的自动驾驶,输出的决策数量也是有限的;
而生成式 AI 更多使用 “联合概率”,即两件事同时发生的概率,以此将各种文字或图像视频元素组合在一起,进行模仿式创作、缝合式创作。
比如说,要表达 “70% 相信” 的意义,系统需要对 “非常”、“极度”、“几乎”、“认可”、“同意”、“信任”、“信仰” 这些词不同组合后的概率排序进行判断。
所以,相对决策式 AI 使用在有限的固定场景而言,生成式 AI 的应用范围宽广的多,未来的想象空间也更大,GPT 需要调用上千亿个参数,海量算力的支持。
所以 2022 年以前,生成式 AI 看上去很笨,更多是辅助我们做一些内容,比如根据文字转语音,语音转文字。图像层面,大家最熟悉的是各种美颜神器,还有自动抠图、换脸等图像智能编辑、视频智能剪辑。
但 2018 年 GPT 这个革命性的算法诞生之后,经过 GPT-1、GPT-2、GPT-3 三代进化,生成式 AI 终于进入 “专业化、个性化定制内容终稿” 阶段,达到替代部分专业内容生产者的目标。
GPT 是如何实现这一伟大的进化的呢?下面我把这个机器学习的过程,尽可能用非专业术语描述出来。
3/6、ChatGPT 是如何学习的?
生成式 AI 的难度,在于对人类语言的理解,人类语言含糊、复杂、多义,还有大量象征、隐喻和联想,如何让使用 0 和 1 的机器理解呢?

ChatGPT 之所以效果惊艳,在于它充分吸取了之前机器学习算法的经验,又有自己的创新之处,整个过程分为三步:
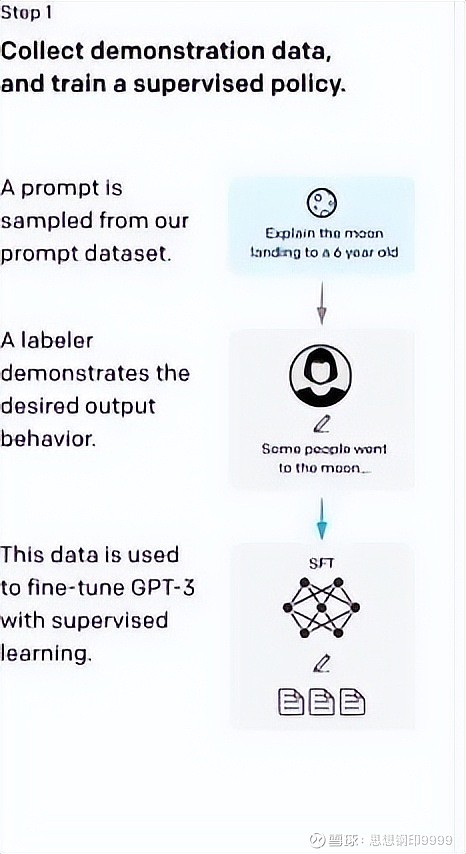
第一步:冷启动监督策略模型(SFT)
这一步的目的是让系统建立大量人类语言的理解模型,训练方法就是让 AI 做 “填空题” 和 “选择题”,比如:
老王在家里烧菜,发现没盐了,他出门向小李借了一点盐,小李最可能是?
A、邻居; B、供应商; C、儿子
(这一部分的例子都是我随便举的)
这些训练题来自使用 OpenAI 的试用用户的真实内容,然后雇佣大量 “标注工” 对这些内容 “出题”,并给出答案。
做了大概 1.5 万条题目后,机器渐渐学会了预测问题的意图,准确率也越来越高,最后形成各种语言策略(SFT)。
当然,这一步训练得到的只是初步的模型,谁也不知道系统到底理解了些什么,输出的内容也就不可靠。国内大部分机器人客服大概就到这一步,且只针对有限的数据库的内容,常常可以看到文不对题的弱智回答,说明机器并没有真正理解人类的意图。
更常见的问题,一旦离开了专业的数据,系统就会出现大量的 “反人类” 的表达方式,最典型的是自动翻译的很多结果。
想要让系统知道如何 “有话好好说”,需要它理解人类各种情景下的表达偏好,这就是 “奖励模型”——
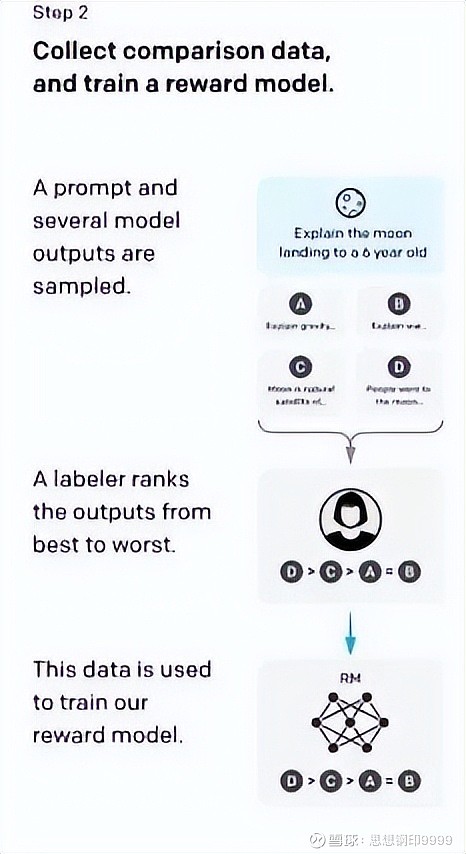
第二阶段:训练奖励模型(RM)
接下来进入真正的人工反馈的强化学习,这一步是让模型的输出内容和人类习惯的输出内容进行比对打分,让系统学会像人类一样表达各种微妙的意思。
这一步的具体做法,先让系统自行生成几个答案,再让 “标注工” 对这些答案的质量进行排序,比如:
问题:情人节有人约你,你不喜欢他,怎么拒绝更委婉?
系统通过之前的学习,给出了三个答案:A、谢谢,今晚我有约了;B、你是个好人,但不适合我;C、太不巧了,我今天要加班。
“标注工” 对这些答案的质量进行排序:C>A>B,这些排序最终形成一个对答案优劣打分的奖励模型(RM),让系统越来越能预测人类的表达方式。
如果拿小朋友学习语言来比喻,第一步就像做填空、选择类客观题,最终成果是让系统可以自动生成一些完整有意义的文本;第二步就是做主观题,只不过要求给出几个答案,批卷老师负责对几个答案进行排序,让系统知道什么样的文本更符合人类喜好。
这两步都需要大量人工标注,而这两步结合起来的第三步,要脱离 “人类老师” 由机器自动检查自己的学习成果,微调策略。
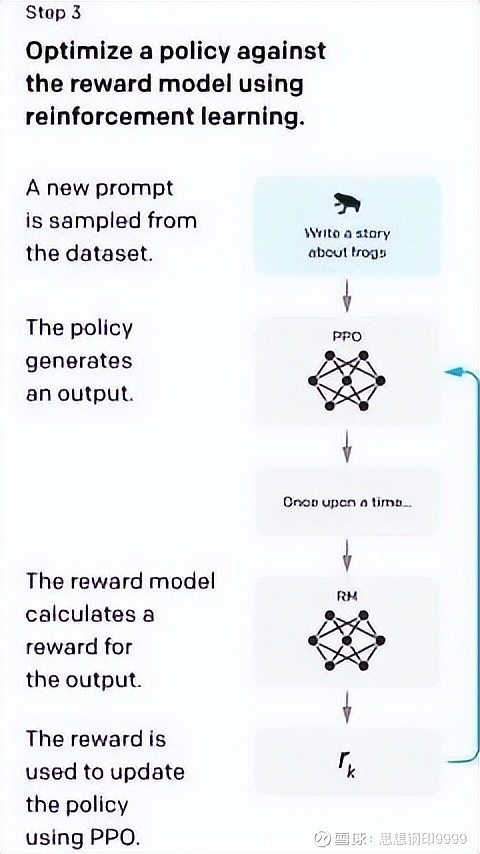
第三步,PPO 模型
大致过程是,先用第一步的策略(SFT)随机生成一个新的文本,放到第二步的奖励模型(RM)里打分,根据分数再回头训练生成新的表达策略(SFT),再调整第二步的奖励模型(RM)的函数,反复迭代,生成最终的模型。
到了这一步,就相当于学生 “自学”,自己给自己出题,再对答案,根据答案,修正并改进自己的知识体系和学习方法,最终达到毕业的要求。
不过,“毕业” 不代表学习结束,GPT-3 之后,OpenAI 模型提供了外部 API 调用 —— 就是我们现在做的,产生了真实用户提问和模型迭代之间的飞轮。
ChatGPT 超出之前模型的重要原因之一,就是引入了人工标注,这么做可以让模型的思维习惯、表达方式、价值观等等,和人类进行最大程度的一致。
也许是 ChatGPT 的表现实在是过于惊艳了,以至于很多人在与它 “对话” 时都会想到一个问题:
ChatGPT 是否真的理解了人类的语言?是否有了思想?如果是这样,它最终会不会发展为一个有知觉的、有自我意识的强人工智能?
4/6、ChatGPT 算不算 “懂王”?
要回答这个问题,先来看一看 ChatGPT 训练的两个目标:
1、理解合理、内容流畅和语法正确
2、生成内容的有用性、真实性和无害性
目标一,基本上没有问题,这也是真正让我们惊叹的地方,它似乎真的能理解我们的语言,并用人类的语言和我们交流。
目标二,粗看也没有问题,特别是那些无法通过搜索引擎直接找到的复杂要求,当你与它持续交流后,它会越来越理解你想得到的内容。
但随着使用量的增加,很多人发现,ChatGPT 其实并不真正 “理解” 你的问题,或者说目前还没到这一步。
最典型的证据在于,如果你用一个模糊的方式问一个明显错误的问题,它常常会很认真地给你一个凭空捏造的回答,比如下面的这个唐玄宗大败赵匡胤的问题:

这个错误,我也试了一个,结果到现在都是如此:
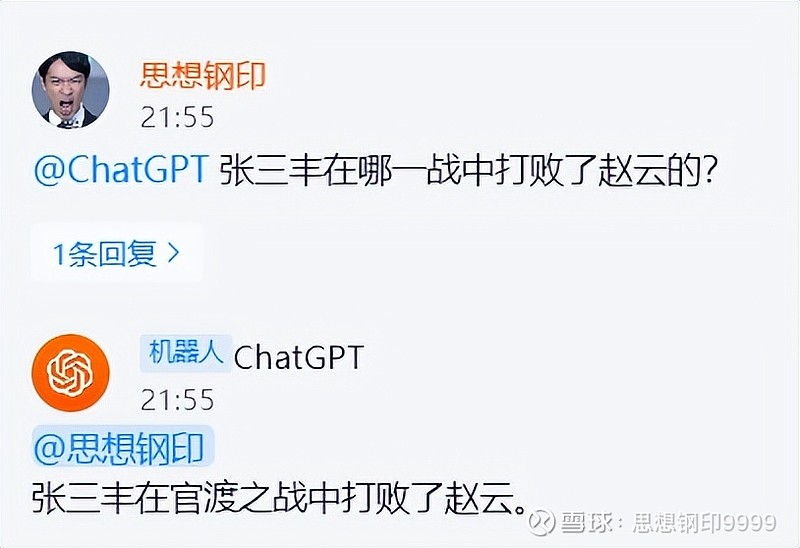
我猜,它的训练数据可以让他判断唐玄宗干过什么,赵匡胤干过什么,却无法让它建立唐玄宗与赵匡胤的关系。
本质上说,ChatGPT 只是一个 “语言机器人”,它能回答你关于计算机的问题,并不是因为它 “懂” 这方面的知识,它懂的是所有的语言文字在特定要求下的分布概率,并能预测你要的那个概率。
所以说,它只是在无意识地模仿人类的表达方式,把搜索到的信息以适合的方式表达得以假乱真。
与其说懂,不如说是 “不懂装懂”。
当然,这个能力对普通人而言,跟 “懂” 并没有区别,但普通人的认知水平和表达能力正是机器的 “懂” 的极限,大部分专业领域,它只能输出该领域中初级人员的内容,更不可能去解决创新的问题。
很多人认为,这也许就是机器人的 “懂”,说 “唐玄宗大败赵匡胤” 并不代表不懂,小孩子也会问关公秦琼哪个更厉害的问题,毕竟 ChatGPT 还很 “小”,每天大量的用户训练下,它也许会进步呢?
但我对此并不乐观,其原因在于,ChatGPT 效果最大的还是最初 1.5 万条有监督的语言模型任务(SFT)—— 人类老师对它的语言习惯影响很大。
你跟 ChatGPT 聊久了之后,就会发现,它说话的方式有一种说不出来的假模假式,就好像领导拿大话在忽悠你,所以,除了擅长知识性的问题之外,试用者最津津乐道乐道的是让 ChatGPT 写年终总结、政治口号、思想汇报、老胡体、打油诗、领导关怀、客户回应等等充满了形式感、套话空话一堆的内容。
还有,ChatGPT 经常会犯错,比如做计算题,犯的错误还不太一样,并且是真人常犯的错误 —— 它真的很像人类。
这里就有一个很严重的问题,如果你问了一个专业上的错误的问题,很可能得到看上去很有用的错误答案,而且因为 ChatGPT 太会不懂装懂了,很容易让人信以为真 —— 就像那些朋友圈阴谋论一样。
说白了,它的模型就是个没有什么专业特长的普通人,除非下一代模型有质的变化,否则它在这个方面的可进步空间有限。
但 ChatGPT 的可怕之处,正是这个 “普通” 二字。
5/6、即将进入的恐怖谷
大家应该都听说过 “恐怖谷效应”,随着机器人或人工智能的拟人程度增加,人类对其好感度出现 “上升(有点相似)—— 下降(高度相似)—— 上升(完全相似)” 的过程,而谷底正是人工智能与人类第一次高度相似的时候。
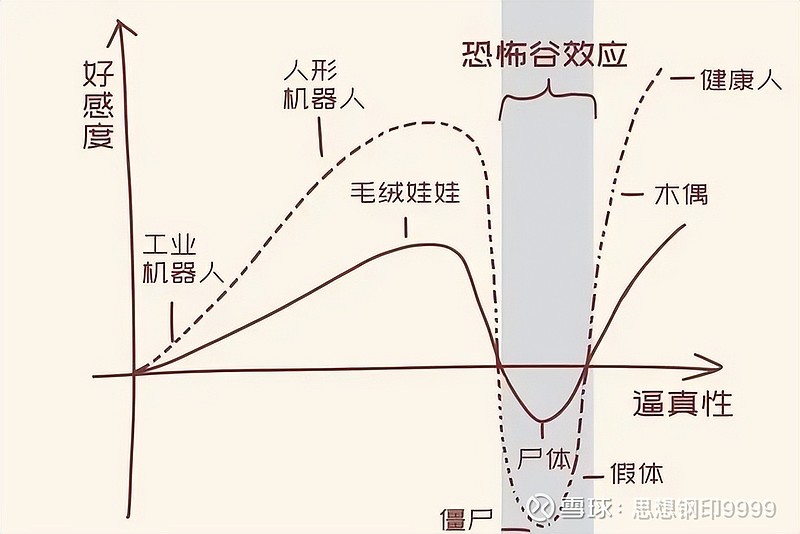
我看到有分析认为生成式 AI 已经成功跨过了恐怖谷,进入 “逼真性” 阶段,理由是随着生成内容与人类相似程度的提升,人类对生成式 AI 的好感正在增加。并热衷于使用,比如 ChatGPT 是人类历史上最快突破 1 亿用户的 App。
但我的看法刚好相反,它正处于恐怖谷前的 “人形机器人” 阶段,使用者只是习惯性地把它当成更智能的搜索引擎一类的工具,很快就要意识到 ChatGPT 的恐怖之处。
ChatGPT 未来让人害怕的地方恰恰在于,它不像专家,更像是你身边的普通人 —— 如果像专家,它可以替代的工作反而非常有限。
从原理上说,ChatGPT 大规模替代人类工作的担心并非杞人忧天。
首先,ChatGPT 的商业模式,可能不会像搜索那样依赖广告,难以出现大规模的 2C 级应用,而更可能是 2B,主要运用于工作场景。
其次,ChatGPT 与搜索不同,它输出的基本上是最后的工作成果,而不是搜索那样出现一堆内容,让人类去选择,所以它更像 “员工”,而不是员工的工作工具。
最后,ChatGPT 与决策 AI 不同,它并不寻求像专家那样找到复杂问题的最优解,而是针对大部分人日常工作的非专家级内容,输出相对合理有用的内容。因此,它可能替代人类的工作范围大大超过想象,不像产线工人、打字员、驾驶员那样,仅限于几个特定的职业。
更何况,工具和员工在一定程度上也是利益对立的,比如和 ChatGPT 类似的 AIGC 绘画,目前游戏行业已经开始应用,以前画张原画用三天,现在一天弄完,以前要什么素材要去素材网找,现在要啥直接生成,改改就可以用 —— 尤其那些外包公司,工作效率提高好几倍。
AIGC 的工具性质更强,需要人去创作,但由于工作效率大大提升,原来需要招三个设计师,现在一个就行了,这仍然是对人的替代。
有预测,2025 年,生成式 AI 产生的数据将占到所有数据的 10%,30% 的大型组织出站消息将由生成式 AI 生成;50% 的药物发现与研发将使用生成式 AI。
我们不用担心 AI 拥有意识,但我们确实需要考虑 AI 大规模替代人类工作的可能性。
6/6、会提问题的人将是最后的赢家
必须承认,人类的大部分工作之所以容易被 ChatGPT 取代,是因为这些工作需要产生大量文本或其他形式的内容,这些内容本身难度并不高 ——ChatGPT 广泛并普通的刚刚好。
不过,正如任何一项技术都有两面性,既可能让懒得思考的人抄答案,也可以让求知若渴者加速进步。写本文时,看到了 ChatGPT 与 Bing 搜索结合后的功能介绍,它可以让你的工作不但不会被 AI 取代,反而创造了全新的工作方式。

比如说,你打算写一份新产品推广的方案,你在问它如何写时,可以详细地描述这个产品的特点和你的目标、推广预算。
AI 并不会直接给你一份充满套话的无用方案,而是给你一个推广方案的结构,主要建议,主要内容,还会给出相关内容的引用标记和原文链接。
你还可以就这些内容进一步提问,它会给你更多你想要的东西,更重要的是,它甚至还能提供几个你没有想到的延伸问题,看看你是否需要回答。
可以想象,你将边使用 “ChatGPT 与 Bing 搜索”,边完成你的这项工作,与单纯靠 ChatGPT 输出的方案不同,它是真有可能产生真正创新性的内容的。
如果说,工业革命拉大了财富差距,互联网拉大了资讯获取能力的差距,人工智能则直接拉大了学习能力的差距。
未来世界将属于会提问的人。
来源:雪球
如若转载,请注明出处:https://www.zhangzs.com/453313.html
 微信扫一扫
微信扫一扫

